Sequenceserver: a modern graphical user interface for custom BLAST databases
← Main Sequenceserver Publication
Supplementary Information
Technical implementation details
We developed Sequenceserver from scratch rather than basing our work on the NCBI’s initial Perl/CGI wwwblast wrapper to reduce technical debt The core of Sequenceserver is written in the Ruby language popular for creating websites and bioinformatics tools while JavaScript and HTML/CSS are used for layout and interactions in the web browser. We use preexisting tools and libraries to facilitate development: The lightweight framework Sinatra is used to create URL endpoints to load the search form and run BLAST searches from the browser. BLAST searches are delegated to the compiled command line version of BLAST we use Ox (https://github.com/ohler55/ox) to parse BLAST XML and create the HTML report. Underscore (https://underscorejs.org/), HTML5 Shiv (https://github.com/afarkas/html5shiv), jQuery (https://jquery.com), jQuery UI (https://jqueryui.com), Webshim (https://afarkas.github.io/webshim/demos), and Bootstrap (https://getbootstrap.com) libraries create a uniform scripting environment (for dynamic aspects of the user interface) and a consistent look-and-feel (for visual layout) across browsers. The d3 (https://d3js.org/) and BioJS libraries are used respectively for generating the graphical overview and the sequence viewing interface. Details regarding versions of the different software libraries are indicated in the source code repository at https://github.com/wurmlab/sequenceserver.
Sustainable software development approach
We followed six software engineering practices to facilitate and accelerate development while increasing robustness, improving the long-term sustainability of the software (). First, we used an open source and agile development approach involving frequent incremental improvements, peer review and frequent deployment on our servers and within the community. Second, we structured the software according to the object-oriented programming paradigm to cleanly separate different parts of code. Third, we followed two important software development principles: “don’t repeat yourself” (DRY) leads to fewer lines of code and thus fewer bugs, and makes it easier to read and understand code than if similar commands are repeated in several places “keep it simple, stupid” (KISS) reduces unnecessary complexity and thus lowers risks and leads to higher maintainability Fourth, we reuse widely established software packages and libraries (see above) to benefit from work done by others. This accelerates our work and reduces the amount of Sequenceserver-specific code, which in turn further reduces the likelihood of adding bugs Fifth, we implemented unit and integration tests for many parts of Sequenceserver’s code, and use continuous integration (https://travis-ci.org/) to ensure these tests are automatically run whenever a change is made to the code, thus increasing the likelihood and speed of detecting errors. Sixth, we use automatic code checkers including rubocop (https://github.com/bbatsov/rubocop) and w3 validator to ensure that our code respects relevant style guides and development principles. Such respect of style standards (e.g., names of variables and methods, code structure and formatting) makes code more accessible to others than if we had chosen no or different conventions Finally, we use the Code Climate platform (https://codeclimate.com) for automated reviews of code quality.
User centric design of graphical user interface
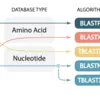
To ensure a fluid user experience that increases researcher productivity, we designed Sequenceserver around eight modern user interface design principles. First, the interface contains only essential information to minimize distractions for the user. Second, the information is laid out in a clear and hierarchically structured manner. As part of this, we paid special attention to typography, using typefaces specifically designed for legibility and aesthetics on electronic devices (Roboto and Open Sans). Third, we used automation where possible to minimize the amount of decisions the user must make. For example, we limit the choices for algorithm selection based on query type and databases selection – this is because only a single basic BLAST algorithm is possible for all cases except for nucleotide-nucleotide search (Figure S1). Fourth, we use interactive visual feedback and cues for step-by-step discovery of the workflow. For example, the BLAST button remains disabled until the user has provided query sequence(s) and selected target databases. If the user tries to click the BLAST button while it is disabled, a tooltip indicates that a required input is missing. Similarly, the selection of protein databases is automatically disabled if the user has already selected a nucleotide database (and vice versa). Fifth, we remain consistent and contextual with regards to user interaction. For example, notification of detection of sequence type does not depend on how the query sequence was provided. This notification is shown below the query sequence input field – where the user is likely to look after query input – instead of using a global designated notification area or displaying pop-up windows that can be disruptive or are ignored. Similarly, a “clear query” button is shown only after the user has provided query sequence(s) and is positioned where a user is likely to look for it. Sixth, we try not to let the advantages of a graphical interface and efforts to create an easily accessible user experience limit the scope of what the user can do. For example, all possible advanced BLAST search options can be entered via a generic input field. Similarly, tooltips over report download links are only shown after the mouse pointer has hovered for at least 500ms. This delay means most users will not be bothered by tooltips after they have used the interface a few times. Seventh, we exploit intuitive human notions of colors. For example, if the user erroneously tries to combine nucleotide and amino acid sequences in the query, the query input-area is gently highlighted using a red border to indicate an error. At a different level, in the graphical overview shown for each query, the color of each hit indicates its strength, with stronger [e-values](/blog/blast-e-value-meaning) being darker. Finally, the wording of error messages is similar to an informal human conversation to create empathy and familiarity, which may also clarify that Sequenceserver is built by a community of scientists.
Supplementary Figure
Table: Research using Sequenceserver
| Interplay of chimeric mating-type loci impairs fertility rescue and accounts for intra-strain variability in Zygosaccharomyces rouxii interspecies hybrid ATCC42981 | |
| A genome-wide association study of non-photochemical quenching in response to local seasonal climates in Arabidopsis thaliana | |
| Taraxacum kok-saghyz (rubber dandelion) genomic microsatellite loci reveal modest genetic diversity and cross-amplify broadly to related species | |
| Developmental expression and evolution of hexamerin and haemocyanin from Folsomia candida (Collembola) | |
| Disentangling the mechanisms of mate choice in a captive koala population | |
| Evidence for sexual reproduction: Identification, frequency, and spatial distribution of Venturia effusa (pecan scab) mating type idiomorphs | |
| Pseudomonas fluorescens group bacterial strains are responsible for repeat and sporadic postpasteurization contamination and reduced fluid milk shelf life | |
| Complete pathway elucidation and heterologous reconstitution of Rhodiola salidroside biosynthesis | |
| Evolution of the shut-off steps of vertebrate phototransduction | |
| De novo draft assembly of the Botrylloides leachii genome provides further insight into tunicate evolution | |
| Whole-genome sequence of the metastatic PC3 and LNCaP human prostate cancer cell lines | |
| Fire ant social chromosomes: Differences in number, sequence and expression of odorant binding proteins | |
| Ecological genomics for the conservation of dwarf birch. | |
| Transcriptomic discovery and comparative analysis of neuropeptide precursors in sea cucumbers (Holothuroidea) | |
| High-throughput genotyping analyses and image-based phenotyping in Sorghum bicolor | |
| Bacteriocins of non-aureus staphylococci isolated from bovine milk | |
| Naturally occurring high oleic acid cottonseed oil: Identification and functional analysis of a mutant allele of Gossypium barbadense fatty acid desaturase-2 | |
| 3D sorghum reconstructions from depth images enable identification of quantitative trait loci regulating shoot architecture | |
| A workflow for studying specialized metabolism in nonmodel eukaryotic organisms | |
| Transcriptomic identification of starfish neuropeptide precursors yields new insights into neuropeptide evolution | |
| Multi-species sequence comparison reveals conservation of ghrelin gene-derived splice variants encoding a truncated ghrelin peptide | |
| Characterization of a second secologanin synthase isoform producing both secologanin and secoxyloganin allows enhanced de novo assembly of a Catharanthus roseus transcriptome | |
| Identification and heterologous expression of the chaxamycin biosynthesis gene cluster from Streptomyces leeuwenhoekii | |
| Discovery of sea urchin NGFFFamide receptor unites a bilaterian neuropeptide family | |
| Comparative analysis reveals loss of the appetite-regulating peptide hormone ghrelin in falcons | |
| Reconstructing SALMFamide neuropeptide precursor evolution in the phylum Echinodermata: Ophiuroid and crinoid sequence data provide new insights | |
| Molecular biology approaches in bioadhesion research | |
| Discovery of a novel methanogen prevalent in thawing permafrost | |
| Neuropeptides and polypeptide hormones in echinoderms: New insights from analysis of the transcriptome of the sea cucumber Apostichopus japonicus | |
| Discovery of a novel neurophysin-associated neuropeptide that triggers cardiac stomach contraction and retraction in starfish | |
| The evolution and diversity of SALMFamide neuropeptides | |
| The protein precursors of peptides that affect the mechanics of connective tissue and/or muscle in the echinoderm Apostichopus japonicus |
Table: Public community websites using Sequenceserver
| Reference / description | URL |
| Genomic resources for the nematode, Pristionchus pacificus | http://pristionchus.org |
| Spotted wing fly-base | http://spottedwingflybase.org |
| JRC GMO-amplicons: Database of amplicon sequences related to genetically modified organisms | https://gmo-crl.jrc.ec.europa.eu/jrcgmoamplicons/db_scans/blast |
| LCR-eXXXplorer: Explore low complexity regions in protein sequences | https://repeat.biol.ucy.ac.cy/fgb2/gbrowse/swissprot/ |
| Planmine: Data and tools to mine planarian biology | http://planmine.mpi-cbg.de |
| Lotus-base: Resources, tools, and datasets for the model legume Lotus japonicus | https://lotus.au.dk |
| ReefGenomics: Genomic and transcriptomic data for marine organisms | http://reefgenomics.org |
| Y1000+ project: Initiative to sequence 1000 wild yeasts | https://y1000plus.wei.wisc.edu |
| gEVE: Database of genome-based endogenous viral elements | http://geve.med.u-tokai.ac.jp |
| EchinoDB: Database of orthologous transcripts from echinoderms | https://echinodb.uncc.edu |
| Assembled transcriptomes of sea bass and sea bream | https://sea.ccmar.ualg.pt |
| Lupin genome portal: Genome assembly and annotations for the narrow-leafed lupin | https://lupinexpress.org |
| Lepbase: Lepidopteran genome database | https://lepbase.org |
| CottonFGD: Cotton functional genomics database | https://cottonfgd.org |
| Hopbase: Database for genomics of Humulus lupulus (hop) | https://hopbase.org |
| LeishDB: Database for leishmania genomic information | https://leishdb.com |
| BLDB: Beta-lactamase database | http://bldb.eu:4567 |
| Hymenoptera genome database | http://hymenopteragenome.org |
| Bovine genome database | http://bovinegenome.org |
| CircFunBase: A database for functional circular RNAs | https://bis.zju.edu.cn/CircFunBase/ |
| Daphnia stressor database: Gene expression database for Daphnia | https://www.daphnia-stressordb.uni-hamburg.de/dsdbstart.php |
| EFISH Genomics 2.0: web portal for electric fish genomic resources | https://efishgenomics.integrativebiology.msu.edu |
| NBIGV, Non-B cell derived immunoglobulin variable region database | http://nbigv.org |
| iBeetle-base: Database of Tribolium RNAi phenotypes | https://ibeetle-base.uni-goettingen.de |
| Cacao genome database | https://cacaogenomedb.org |
| Ant genomes, predicted transcripts and proteome | https://antgenomes.org |
| Aplysia transcriptome | https://aplysiagenetools.org:4567 |
| Ash tree genome | https://ashgenome.org |
| Asparagus genome project | https://asparagus.uga.edu |
| Firefly genome database | http://blast.fireflybase.org |
| Genome, predicted transcripts and proteins of tardigrades | http://blast.tardigrades.org |
| Botulinum neurotoxin database | https://bontbase.org |
| FusoPortal: A Fusobacterium genome and bioinformatic repository | http://fusoportal.org |
| NCHU fish genome database | https://lep-fish.nchu.edu.tw:4567 |
| Fish genome database | http://brcwebportal.cos.ncsu.edu:4567 |
| MarpolBase: Genome database for the common liverwort, Marchantia polymorpha | https://marchantia.info |
| MitoFun: A curated resource of complete fungal mitochondrial genomes | http://mitofun.biol.uoa.gr |
| Oat genome | http://oatgenomeproject.org |
| Spiny mouse transcriptome | http://spinymouse.erc.monash.edu |
| Measles, mumps, and rubella viruses database and analysis resource | http://mmrdb.org |
| 10.1093/dnares/dsz003 Genome database for Iberian ribbed newt | http://inewt.nibb.ac.jp:8111 |
| Crop genomics lab’s BLAST server | http://plantgenomics.snu.ac.kr |
| Exome of Kronos durum wheat and Cadenza bread wheat mutants | https://wheat-tilling.com |
| Gene expression analysis and visualisation for wheat | https://wheat-expression.com |
| Fungal genomics | https://fungalgenomics.science.uu.nl |
| Stazione Zoologica Anton Dohrn | https://glossary-blast.bioinfo.szn.it |
| Desplan Lab (Drosophila developmental biology) | http://desplan-lab.bio.nyu.edu |
| Commonwealth Scientific and Industrial Research Organisation | http://hieracium.csiro.au |
| Institute of Cytology and Genetics of Siberian Branch of the Russian Academy of Sciences | http://seqserver.sysbio.cytogen.ru |
| Taiwan Agricultural Genomics Resource Center | https://tagrc.org:4568, https://tagrc.org:4569 |